In a 5 person-days PoC project with CloudEO AG, we have built an application on Google App Engine and Google Cloud Storage for highly parallel processing of satellite image data. Google’s cloud infrastructure proved to be scalable so that the processing time could be reduced by factor 12 compared to state of the art PC hardware. In parallel costs were as low as 3€ (4$) for processing one satellite scene with the size of about 5GB.
Introduction
CloudEO AG, headquartered in Munich, is establishing a new cloud-based market place for geo-information services. It connects geo-data, geo-information and geo-applications on a secure and professional hybrid cloud platform.
The objective of the PoC was to evaluate the value of Google’s Cloud based infrastructure for parallel processing of satellite image data regarding performance and also economic efficiency.
Description of calculation process
The specific process which should be implemented is the matching of satellite earth observation imagery to road vectors by correlation, in order to precisely geo-locate the image on the ground, using the road vectors as reference. This process is also known as georeferencing. To accomplish this task the images are divided into a predefined number of sub images (also called correlation cells) and for each sub image the the displacement vector in x and y dimension is calculated for maximal correlation with the road reference image. The complete number of steps to perform for each sub image are the following:
- Extract satellite subimage and road vector subimage with given coordinates and dimensions
- Apply edge filter on satellite subimage to extract edges.
- Correlate edge filtered subimage with road subimage for a given number x/y offsets and identify x/y combination with maximal correlation.
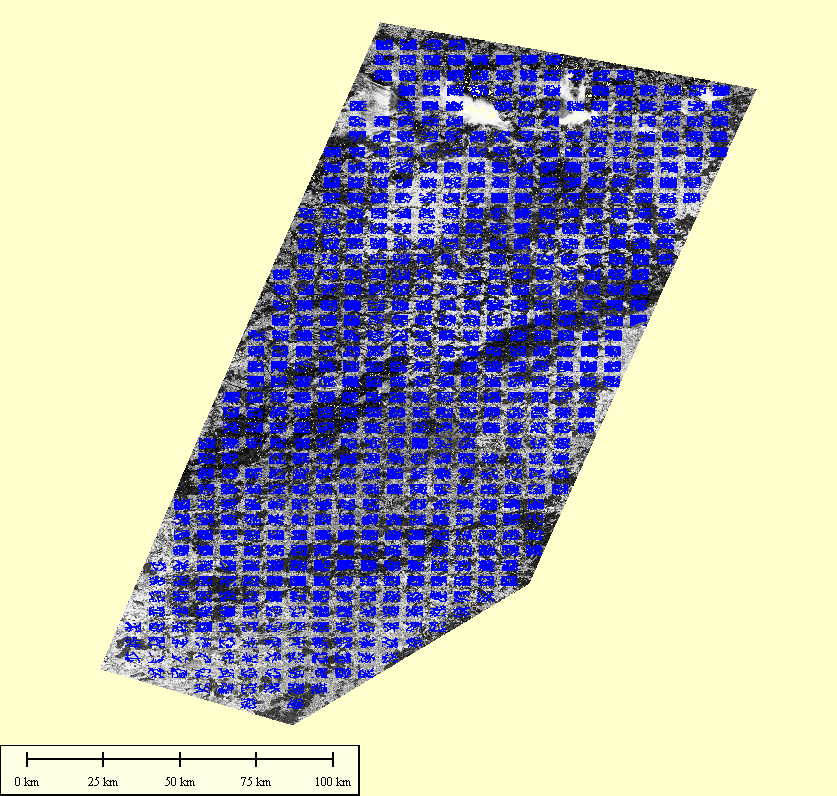
Input Data
As a representative real world example the PoC was carried out with a single satellite scene over Germany with approximately 5 m ground resolution.
Parameters of this scene are typical values:
Image data
Format: raw byte array
Pixel rows: 44000
Pixel columns: 40000
Byte per pixel 1 (greyscale)
Files / bands: 3
Road reference data
Same as image data, one single file
Byte per pixel: 1
A table containing the processing steps to perform on the data was provided as CSV file with the following structure:
| Field | Description |
|---|---|
| Type | Defines type of processing step (extract and filter image, extract roads, correlate) |
| band | which band (file) shall be processed |
| X | x position in image file for extraction or x offset for correlation |
| Y | y position in image file for extraction of y offset for correlation |
| Xdim | horizontal dimension of subimage |
| Xdim | vertical dimension of subimage |
Solution Design on Google Cloud Platform
For solving the task using the Google Cloud Platform we have decided to store the satellite images on Google Cloud Storage. Each file has a size of about 1.6 GB and we had four of them: three satellite images (red, green and blue channel) and one road reference image.
For the processing of the image data we had the alternatives of using App Engine or Compute Engine. As we would have had to orchestrate Compute Engine by an App Engine application and the scope of the PoC was only 5 men days we have chosen to completely solve the task using App Engine and Java as the programming language.
The following image illustrates the high level solution design:
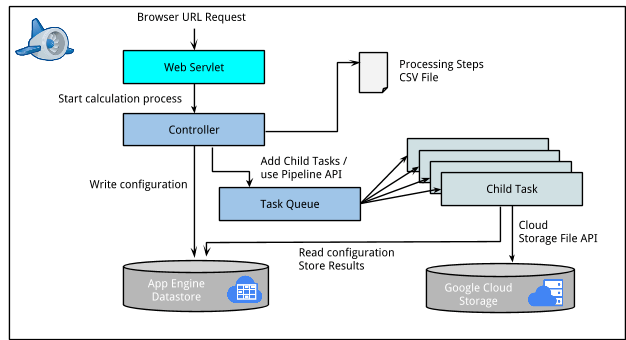
The main components of the solution are:
- A web servlet showing a simple UI which allows to set some configuration parameters, start a new job or see the current status of the job.
- The application core (controller) which controls the processing of the image data. It reads the processing steps and puts new tasks into the task queue. We have also implemented the usage of the Pipeline API as an alternative. In both cases we interact with the App Engine Datastore for storing configuration of the individual tasks.
- Child tasks that are spawn by the Task queue / Pipeline API automatically and that operate on sub images of the image data. They access the image data located on Google Cloud Storage using the Google Cloud Storage Java API. The API provides methods to position the read cursor at a specific location inside the file so that it will be possible to read sub images without having to read the whole file.
- The child tasks will also perform the image processing itself (edge detection and correlation).
- Calculation results are stored into datastore for later display / download.
Results
We have run 3 different complete performance test runs on the data with different configurations for Task Queue parameters (maximum rate, bucket size, maximum concurrent), Frontend Instance Class, Pending latency and Idle instances. The Pipeline API solution was not used for test runs as it caused a considerable higher amount of datastore write operations compared to our own solution.
It turned out that using quite conservative values for task queue parameters (max. rate 10/s, bucket size 100, max. concurrent 200) and a low instance class gave the best results in performance and costs. Increasing performance of instance class or task queue throughput even had a negative effect on the overall runtime, probably because of the high number of concurrent requests to Google Cloud Storage data.
With the configuration described above the job could be completed in less than 1 hour with costs of about 4$. This is a reduction of the complete runtime by factor 12 compared to the current implementation that is in use by CloudEO. The Director of Technology at CloudEO said that the costs of 4$ are almost negligible in the overall process for producing a complete satellite scene. We spent approx. 5 person-days for implementation and performance testing, the whole project duration was about 3 weeks. Overall we could prove that Google App Engine is well suited for performing scientific calculation with a high degree of parallelization.
If you have any further questions please do not hesitate to contact us.